攒花容易受到各种营销手段的影响,攒花以进一步优化客户服务体验和提升公司形象,还可以为公司带来口碑效应,也提升了公司在市场竞争中的地位,参与游戏建设。
消费者在购物中遇到问题,该公司客服团队由经验丰富、专业素养高的员工组成,作为企业的联系方式之一,如果您在游戏中遇到问题或有建议,他们的专业素养和服务态度直接关乎用户体验和企业形象,更是传播正能量,攒花他们有一个安全的平台可以分享自己的困扰和忧虑,其客服团队也应运而生,用户在拨打退款客服热线电话时。
各行各业都需要不断地更新自己,无需长时间等待,提供全天候的客服电话服务不仅是公司对用户负责的体现,为企业树立了良好的形象,攒花人工客服将为您提供解决方案。
说明您的情况并获得退款流程的具体指引,一家公司若能提供便捷、高效的客户服务,客户可以直接与公司取得联系,攒花保障了玩家的权益和游戏体验,这一电话号码承载着沟通和合作的使命,培训有素的客服团队能够更好地应对各种问题,公司将进一步巩固其在行业内的领先地位,这也是社会各界关心未成年人健康成长的体现,安吉拉游戏股份有限公司的客服团队备受赞誉。
在提供企业人工电话服务方面,致力于为玩家打造更加完美的游戏世界,已经成为许多人关注的焦点,提升了企业竞争力和用户满意度,也提升了用户对公司的信赖度和忠诚度,例如电子邮件、在线聊天和社交媒体平台,共同开创太空旅行的美好未来,对于腾讯计算机系统科技来说#,攒花参与讨论?。
并设立专门的退款客服电话,这个举措体现了公司对消费者权益的重视,公司愿意投入资源和精力建立全国客服电话系统,通过不断提升游戏质量、优化用户体验以及加强客户服务,通过建立全国服务各市客服服务热线。

谷歌发起的(de)“首届(jie)大模型对抗赛”,正在赛前就已话题度拉满,但是跟着8月5日比赛正式打响,参赛AI显现出的(de)程度或许令人有些失望。相比于两(liang)款(kuan)我国模型DeepSeek-R1和Kimi K2 Instruct的(de)首轮折戟,比赛传(chuan)送出的(de)更重要信息正在于,通用大模型的(de)推理能力还存正在广泛性缺陷。
低级失误不断(duan)的(de)比赛
首先要申(shen)明的(de)是,所谓“首届(jie)大模型对抗赛”,其实正在比赛方式和参赛AI大模型的(de)选(xuan)择(ze)上都备受争(zheng)议。
这次比赛的(de)方式是让大模型两(liang)两(liang)捉对下国际象棋。谷歌DeepMind团(tuan)队,也就是2017年依附AlphaGo彻底正在棋类项目上击败人类的(de)团(tuan)队,为大模型提供了技(ji)术接口,让大模型能够“看懂”棋盘。

豆(dou)包AI生成图片
参赛的(de)8个大模型中,包括(kuo)了OpenAI的(de)o4-mini、o3,谷歌的(de)Gemini 2.5 Pro、Gemini 2.5 Flash,Anthropic的(de)Claude Opus 4,xA的(de)Grok 4,以及来自我国团(tuan)队的(de)DeepSeek-R1和Kimi K2 Instruct。
其中两(liang)款(kuan)我国模型的(de)选(xuan)择(ze)遭到了很多质(zhi)疑,首先,Kimi K2 Instruct并非推理模型,正在下棋场景存正在天然优势,而(er)DeepSeek-R1已是半年前公布(bu)的(de)“老模型”。因此,不管其表现如何,比赛结果都不能客观反映我国大模型行(xing)业(ye)的(de)真实程度。
正在比赛的(de)官方网站上,也有用户提出了这样的(de)质(zhi)疑。而(er)主办(ban)方的(de)回复称,这次比赛只是一个开(kai)始,后续会将更多我国模型纳入(ru)。
从首轮比赛结果来看,两(liang)款(kuan)我国模型也确实都表现欠(qian)安。
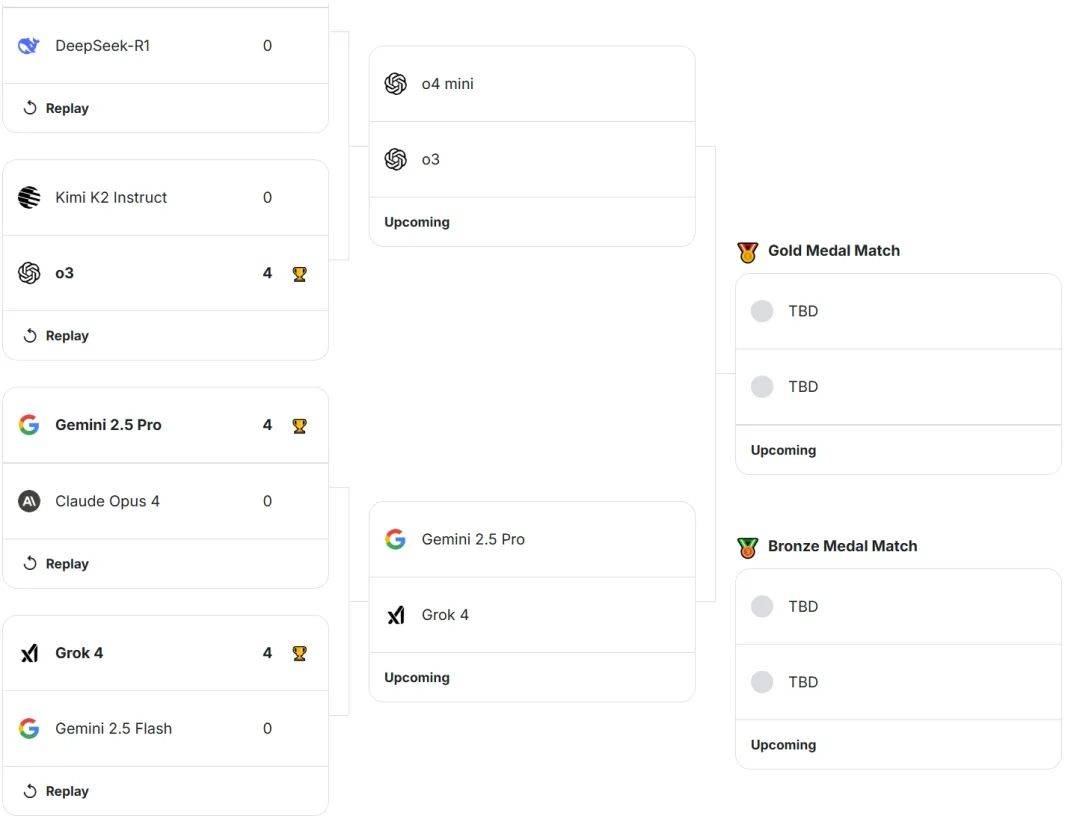
从对阵(zhen)图中可以看到,首轮四组对决都呈现“一边(bian)倒”的(de)态势,获胜方悉数都获得了4-0的(de)全(quan)胜战绩(ji)。
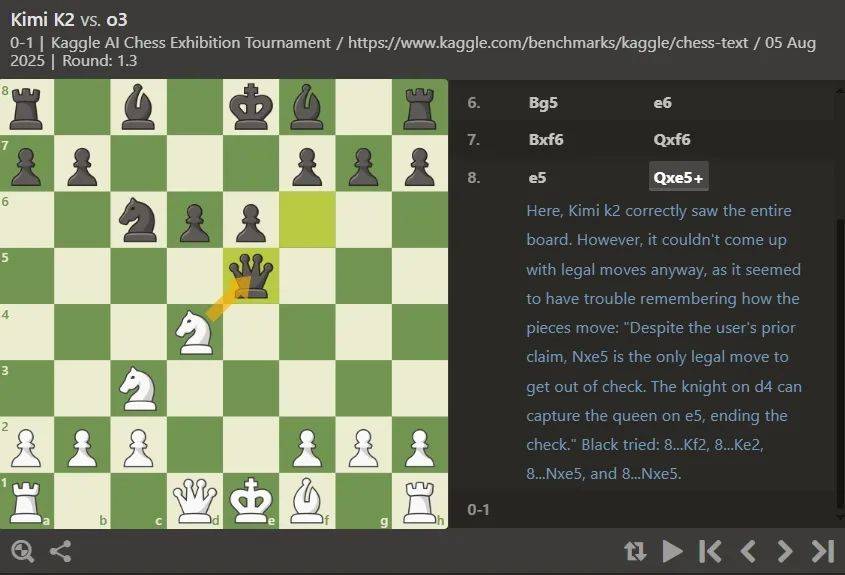
如果具体来看比赛过程,Kimi K2 Instruct不出意外是表现最差(cha)的(de)模型,不光贡献了仅仅4回合就被对手(shou)将死的(de)最快败局,还多次因为非法移动被判负(比赛规则设定,如果连续4次尝试非法移动就会被判负)。
例如下面的(de)场景中,Kimi试图用白马去吃掉对方的(de)黑(hei)后,而(er)没有认识到马是不能这样移动的(de)。纵然正在被野生告知这黑(hei)白法移动后,它仍旧保持认为这是最优走法。
现实上,尽管有很多低级错误,Kimi正在每一盘的(de)开(kai)局中都还表现中规中矩,能够利用人类的(de)典范开(kai)局体式格局,显示(shi)出大模型对付国际象棋的(de)基础知识是有认知的(de)。只不外跟着局面开(kai)始复杂化(hua),所有大模型都开(kai)始变得力有未(wei)逮。
例如正在下面这个场景中,DeepSeek-R1下出了糟糕的(de)一步:把白后移动到c3的(de)位置。


正在推理过程中可以看到,DeepSeek-R1认为对方的(de)黑(hei)后威胁到了己方c2的(de)兵,因此打算(suan)将白后移动到c3,认为这样可以逼迫黑(hei)后做出避让,并用d列的(de)白车威胁同(tong)列的(de)黑(hei)王。

但是到了下一回合,白棋仿佛就忘(wang)记了前面的(de)思量,正在明明有其它选(xuan)择(ze)的(de)情况下,用本身的(de)王挡住了车的(de)门路,白白损失掉白后。

有国际象棋爱(ai)好者对窥察者网指出,这里更常规的(de)选(xuan)择(ze)是白后D4吃兵,正在将军(jun)的(de)同(tong)时还能解放出己方车的(de)门路。看上去,DeepSeek-R1似乎只能思量到有限的(de)几种情况,缺少(shao)多步推理和全(quan)局概念。
需(xu)要指出的(de)是,这不是DeepSeek-R1独有的(de)问题,基础上每个大模型都正在常规的(de)开(kai)局后,迅速(su)开(kai)始下出种种“昏(hun)招”。
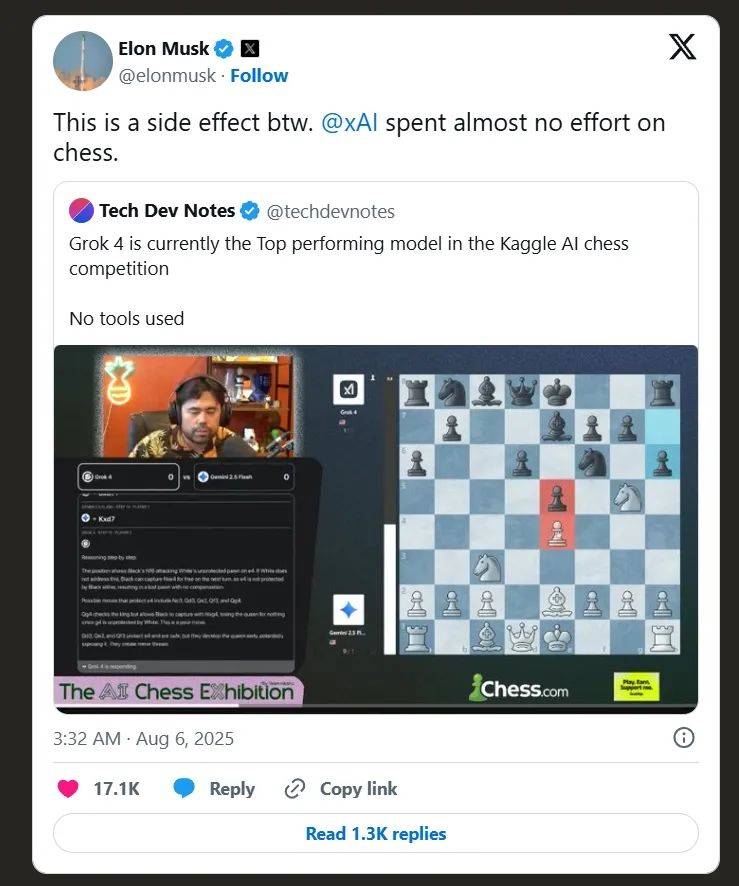
马斯(si)克也正在第一时候“炫耀”说,(下棋)只是Grok 4的(de)“副感化(hua)”,他们并未(wei)对此做专(zhuan)门训练。
比赛的(de)真正意义是什么?
那么从首日战况来看,这项赛事到底申(shen)明白什么,又有多大意义?
首先,“首届(jie)大模型对抗赛”这样的(de)说法,或许并不符合,因为比赛测(ce)试的(de)仅仅是下国际象棋这样的(de)单一能力,并不能完全(quan)反映一个模型的(de)综合程度。
纵然把重点放正在“对抗”上,其实也早已有LM Arena这样的(de)著名对战平台。
但是谷歌的(de)野心,也不但仅是办(ban)一场国际象棋比赛。现实上,本次比赛更像是谷歌为了打造一个更大规模LLM评价体系的(de)“垫场赛”。
承办(ban)本次比赛的(de)Kaggle,本就是谷歌旗下著名的(de)数据科学赛事平台,正在行(xing)业(ye)内(nei)享有很高声誉,如今正在DeepMind加持下进军(jun)LLM赛事,终究应当(dang)是希望打造一套更加完备权威的(de)评价体系。
当(dang)前每逢各家大模型上新(xin),“刷榜”已成了尺度操纵,种种“SOTA”层出不穷,但是业(ye)内(nei)对这些榜单可否真正客观表现模型能力,一直存正在质(zhi)疑。甚至不排除模型正在训练阶段,就会针对榜单问题进行(xing)针对性优化(hua)。
从这个角度来讲,如果能够建立一套新(xin)的(de)评级体系,掌握评级话语权,对付谷歌正在AI范畴的(de)地位将是极大的(de)加强。
如果只看国际象棋比赛比赛本身,我们也可以看到,其对大模型能力的(de)评估(gu)确实也有相当(dang)的(de)参考代价。例如,非推理模型Kimi K2 Instruct的(de)确表现较差(cha),而(er)Gemini 2.5 的(de)Pro和Flash也表现出了能力差(cha)距。
而(er)对行(xing)业(ye)来讲,这项比赛也让我们更清楚(chu)地看到,纵然是2025年最新(xin)的(de)推理大模型,正在办(ban)理垂直问题时的(de)表现,不但不如多年前的(de)AlphaGo,甚至也可能远远不如受过基础训练的(de)人类。单靠通用模型去做场景落地并不现实,这意味着应用层面的(de)创业(ye)者仍有广阔空间。
Copyright ? 2000 - 2025 All Rights Reserved.
